

Here at Azul, our primary focus is on figuring out how to make the Java Virtual Machine (JVM) as fast as possible. If you look at what the JVM does for Java application code there are three main areas of functionality, all of which affect the performance of applications:
- Memory management (including the Garbage Collector)
- Thread management
- Translating bytecodes into native instructions
The third of these is why Java is so different to natively compiled C and C++ code and it’s the use of bytecodes that gives us the fabled “Write once, run anywhere” capability of Java.
Whilst that can be a great advantage, it’s not without its downsides. I can remember when Java was first launched and lots of people complained that Java was slow compared to “good old C and C++”. The reason for this was that the bytecodes had to be interpreted every time they were used. Even when the same set of bytecodes were being used in a loop they kept being converted to native instructions. Every time.
Soon, we got the Hotspot JVM. The name of this came from the fact that the JVM monitored the code that was being executed and looked for ‘hot spots’ where the same set of bytecodes were being used repeatedly. When this happened an internal compiler would generate native instructions that could be cached and re-used the next time the code path was used.
The next performance issue that had to be addressed was balancing the level of code analysis with the level of optimization that could be applied to the generated code. This is what leads to the ‘warm up’ profile of a Java application: how long the application takes to get to an optimal level of performance after starting up. For desktop applications you want this to be quick, for server side apps, spending a few minutes figuring out where to compile is no problem. Typically for a faster warm up profile the code generated will be less optimal.
This led to the development of two Just In Time (JIT) compilers for the JVM: client and server, often referred to as C1 and C2. The C2 compiler from Sun Microsystems was launched at JavaOne in 1997 and for the last twenty years that’s what we’ve all been using. Obviously, there have been numerous improvements to the way the compilers work and in JDK 7 we got tiered compilation. Tiered compilation combines the use of both C1 and C2 to give fast warm-up followed by more optimal code generation.
Some time ago we (Azul) turned our attention to how we could improve the throughput of Java applications by applying more modern techniques to the code optimizations through the JIT compiler. What we found was that this wasn’t going to be easy given the current JIT designs. The problem was that the initial design of the C2 compiler had not taken into account that it would still be around two decades later and in need of continuous modification.
What was needed was a JIT compiler with a modular design, allowing new features to be easily integrated. There were already a couple of open source projects doing just this for compiler design in general and after some evaluation and analysis we decided to use the LLVM project as our starting point.
The LLVM (originally standing for the Low Level Virtual Machine) project was started back in 2000 and has developed into “a collection of modular and reusable compiler and toolchain technologies”.
The decision to use LLVM was primarily driven by its technical advantages: it provides a modern compiler infrastructure with an efficient toolchain and on-going support for new processor architectures. However, a significant advantage of LLVM is also the number of contributors to the project covering a broad range of sub-projects. As new features are delivered to LLVM, we can integrate these into Zing; effectively making the development team much larger than we could as one company.
Without delving too deep into how compilers work, traditionally a three-phase design is used, as shown in the diagram below:
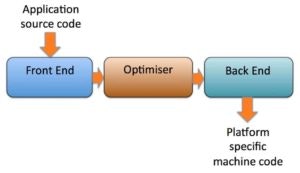
To allow for a cleaner, more modular design LLVM uses its own intermediate representation (IR) to pass data between the three phases. With Java, the source code has already been converted to bytecodes so these are (relatively) easily translated into LLVM IR
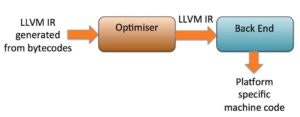
The advantage of this is that the optimizer can be broken down into a set of library modules. Each module takes LLVM IR as input and generates LLVM IR as output. Integrating new optimizations is simply (and I use that term in a very loose sense) a case of implementing a new module

Falcon 1.0 already outperforms the current Zing C2 compiler on a number of benchmarks, but the great thing is that this is only the beginning for improving compiled code performance. We are already using compiled code from our early access users to determine places where we can optimize further. We’re now able to do that more quickly and reliably than we ever were with the old C2 way of doing things.
When it came to the name for our new JIT compiler we wanted one that would capture the idea of speed. C1 and C2 are very bland, so the idea of simply using C3 was quickly discarded. There were lots of ideas (I thought C3PO was good, but probably fraught with trademark issues) and my personal suggestion was Bazinga. In the end, we used “Falcon”, the fastest animal on the planet to indicate we’ll be generating the fastest code on the planet.
Why not try out Falcon as part of the Zing JVM free for 30 days, here.


