
Until you know which Java applications, frameworks, platforms, and tools are running in each of your environments — along with the Java version of Java and operating system they are using — how can you propose a realistic budget and timeline? Still, many organizations require developers to have this proposed budget and established timeline before they begin assessing their Java estate.
To conduct a successful migration, your organization should walk hand-in-hand with SAM team, application owners, and compliance. This team alignment will help avoid the chicken-and-egg problem by better clarifying the work to be done during the actual deployment of the OpenJDK packages (execution) and testing (validation).
Migration method terminology
These are some common phrases and terminologies we use to describe the migration method and details across this text:
| PHRASE | DEFINITION |
|---|---|
| Compensation actions or steps | Number of additional actions that will have to be performed to overcome challenges during the migration project, e.g., additional third-party product installations and configurations. |
| Focus team | Migration project dedicated team, usually formed by a project manager, IT architect, and a Java SME (principle engineer). |
| Bucket classification | Java runtime/SDK is installation is added to specific migration groups/sets called buckets. The buckets can be named based on specific project constraints and/or features, but will usually follow the same standards: Looks like garbage, Needs further investigation, Bundled to a product, and Ready for migration. |
| Dry-run execution/approach | Quick execution with minimal environment change and preparation, e.g., migration execution quick switch. |
| Sanity checks or sanity tests | Quick infrastructure tests to validate if the application is running or not on target environments, e.g., Is AppServer started and the application is loading its first page without any error? |
| Quick switch | Quick change to OpenJDK using symlinks without installing the runtime. Used to quickly verify the migration (sanity-checks). |
| Quality gauges | Migration internal metrics used to evaluate the health of the project. These gauges are usually related to non-functional requirements, e.g., performance metrics. |
Quick summary of activities required for a successful migration project
- Define the migration “focus team.” This is the dedicated team selected to execute the migration project. It usually consists of one PM, one IT Architect, one SAM engineer, and a number of SMEs that could be pushed to the project as needed.
- Inventory the Java estate. FS crawlers are a better option since the Java runtime usage doesn’t need package managers to be deployed to server platforms and desktops.
- IMPORTANT: Use scripts to quickly classify the installation paths. By running a quick analysis on the installation path, it’s possible to determine (infer) the product bundled with the Java runtime.
NOTE: 99% of all FOSS products and distributions support some version of OpenJDK. By running a quick FS classification on the Java runtime installs (described above) it’s possible to classify these products as “Ready-for-Migration.” The only thing missing will be to define the migration procedures, s.g., Solr is fully OSS and supports OpenJDK, with a “minimal“ environment impact and change.
- Identify the application owners and environment custodians. Application details are crucial for product classification. More details later.
- Identify specific product SMEs. Some products required special configuration for execution. For most cases simple changes in the environment should be enough, e.g., changing the JAVA_HOME environment variable.
- Conduct Application Interviews – Internal Component Architecture. There are several ways to classify an application, but team standups are the fastest and most reliable way to get information from the application internals. Usually, 1-hour standups with a select group of applications (i.e., most likely critical-functional applications) will be enough to collect details about the application architecture. Your target audience will generally be application architects or QA engineers. The inputs for the standups can be an initial questionnaire.
NOTE: It’s not important to gather “functional” details, only component architecture, e.g., does your application generate PDF reports on the server side?
- Application and product details – classification properties. Some applications require specific configurations, but most of them use common Java standards. Classification properties are the specific OpenJDK requirements to run a product, e.g., add custom CAs to the OpenJDK carcerts file, environment variable configurations, or OS based changes (e.g., install of missing libraries).
NOTE: You can apply Techniques to quickly get the information needed, including analyzing the OS process table and hierarchy.
- Prepare the bucket classification. The first level of bucket classification comes with the automation (i.e., FS analysis), and this will quickly distribute the JVM installation into different domains. The final work is to consolidate the details thus far in a final bucket classification with each JVM/product installation detail set as classification properties. Simple example:
- Inventory data: Oracle JRE version 11.0.11.
- Bucket classification: Ready-for-Migration.
- Classification data: Normal JEE application packed in an EAR file.
- Classification properties: OS: Linux RedHat Enterprise, version 8.9. AppServer uses the JAVA_HOME environment variable to identify which Java runtime it needs to use. The Java runtime is configured within a user profile named “appserver,” and the Java environment details (e.g., Path, CLASSPATH, etc.) are all in a file called “.java” on this user’s root folder. This profile file is called by another profile file in the user’s root folder named “.bash_profile.” This is not a pacman (RPM)-based installation; it needs tarbal unpacking and manual configuration (multi-purpose server).
- Classification MISC data: Application resolves all its library dependencies using a Maven private repository implemented in Nexus.
- Validation details: Most of application functional testing is automated using Protractor.
- Additional info: Application deployment and Java runtime configuration is done using Jenkins pipelines – change will be needed to include OpenJDK deployment as part of the application CD pipeline.
- Construct the migration Data Warehouse. Although not required, breaking down the classification details into specific entities (or cubes) may be helpful to generate quick reports and data consolidation during and after the migration.
- Make sure all license products have actual licenses. Most oracle products come with embedded Java runtime licenses1 for the purpose of the application. Developers usually have local admin privileges and can download these Oracle products directly from the Oracle website (e.g., Oracle RDBMS). Having the Java runtime licensed with an Oracle product doesn’t mean that product is licensed (e.g., Oracle instant client). Compliance teams (IT Governance) should be able to help you quickly analyze and classify the inventory for these cases.
- Execution should follow a 3-stage process: Quick switch, commit changes, Java runtime removal. More details below.
- Run internal audits. After executing the first migration batch, it’s important to schedule periodic audits in the migration environments. Use SNOW or Flexera to retrieve that information – tools commonly used by Oracle during audits.
- Validation and Ergonomic Test Strategy. QA engineers usually follow a very strict process to validate an application change or new feature. Think of swapping from Oracle JDK to OpenJDK as an OS patch update. You don’t usually “fully” run application E2E scenarios for regression testing; you only validate sanity checks and a few selected core functionalities. This is called smoke testing. In some cases, for low priority, FOSS bucket-classified JVM products (e.g., Solr), only running sanity tests will suffice, e.g., product started without any problems.
- Stabilization phase. This is a post-migration phase, where all migrated environments should be monitored to catch issues that didn’t occur during execution and validation.
Migration Preparation

Since similar products have similar functionality and usability, most Java-based systems can be combined and classified into application groups. The classification of these groups is important because they are used to consolidate application-specific procedures that are needed by an external OpenJDK installation. Most server products today provide a very clear path for OpenJDK. These steps should be collected during the discovery phase, e.g., specific product procedures for OpenJDK like Claris FileMaker.
For cases where additional steps are necessary (e.g., installation of third-party software like IcedTea-Web), the bucket classification properties are very important for validation and for execution of the migration in an optimal time. This means running the installation scripts with the compensation steps (specific product procedures defined in the classification properties) for a single application running under OpenJDK is sufficient to sample “all” other applications defined in the environment group3. Thus, the remaining steps for these other environments can be generalized (summarized) as follows:
- Document the procedures taken during the migration
- Replicate the procedures on all remaining applications in the environment group
Application classification should also be defined by purpose (e.g., seamless/critical/future), type (e.g., Integration Hub, AppSever), and versioning. In practice, once one server is discovered within the group (i.e., dry-run configuration), all remaining configurations can be easily replicated to all others (full rollout).
Simple Example: An ELK 8.5 (versioning and type) cluster of 10 nodes distributed across 10 critical platforms must be validated once, in only one node (purpose). All remaining nine nodes can be sampled around the same techniques and procedures used during that specific OpenJDK migration. Cluster configuration is defined at the “application” level, not the “OpenJDK” level. No need to verify cluster configuration of even network configuration (e.g., VIP, VMAC, IPSec, etc.) on the JVM level.
Another important factor is the OpenJDK risk matrix categorization. Some very specific migration cases will have to define compensation actions based on these common problems found during migration for old versions of the Java SE. Most servers/desktops migrations will not need to have these compensation actions, but their main purpose is to mitigate and guarantee that all transitions between Oracle JDK and OpenJDK are as seamless as possible.
The best way to mitigate these OpenJDK risks is to use an OpenJDK risk assessment matrix (details below). But if that option is not available, you could use other techniques to assess the application usage and features, including:
- JDK version analysis. (e.g., JDK11+ doesn’t support Java Web Start or Applets, no risk here)
- Java package introspection. (e.g., analyzing JAR/WAR/EAR files for library dependencies including XML configuration, spring property files, YAML files, and others). Example use case: If an application has a JNLP config file defined as part of its WAR package, it has support for Java Web Start, meaning all desktops being served by this application should be migrated with ITW configured.
- Application name and version. By knowing the OOTB product name and version, it’s possible to infer the library dependencies and plan ahead possible workarounds. Example: Solr 8 only uses the standard Java runtime API, meaning no need for any additional step (compensation action) to migrate to OpenJDK (Seamless bucket classification). Also, clever techniques, including application listing in production, can be easily extracted by the inventory tool, by introspecting all live Java processes running on servers.
- Power user (selected users) interviews. For desktops, identifying key applications users would help sampling the Java products and features used on these environments.
- Application documentation. Information coming for internal documentation repositories can be helpful to identify specific Java application usages and features, e.g., Javadoc, user manual, etc.
- Internal application repositories. Analyzing organization-wide artifact repositories like Nexus or SonarQube could help identify application-specific needs and dependencies (e.g., Maven pom files).
When information may not be sufficient to identify these risks, meaning they could not be mitigated directly because of missing information, you can take preemptive actions prior to the migration, e.g., Monotype fonts installation on the server side. The decision for those actions are mainly based on the sampling of Java applications and their server configurations.
The Migration method
Classification starts with an Application Teams Workshop.
During inventory classification it’s very important to identify the custodians of every server/desktop environment identified in your Java estate. Associating environments to their right owners (i.e., application owners) will help you quickly identify your migration stakeholders.
For example, say you install a systemwide JDK and you configure your application to use this JDK. When you run an inventory tool, the inventory will not reflect the application using this standalone Java runtime.
Get your stakeholders in one room. A virtual room, anyway. Typically, this will include the product manager and application architect, and possibly application owners and power users. Depending on the size and structure of your organization, the number of people may be as few as two or more than a dozen. At least one meeting with each application team involved will be necessary.
The purpose of these team meetings (or team workshops as they are usually called in Agile) is to collect as much information as possible about the application non-functional requirements and component architecture. Ideally you want a set of consolidated node and component diagrams and documents. You will need those documents later in the process to help you classify the applications involved in your Java migration.
Every organization will have its own strategy for development lifecycles. OpenJDK migration is an infrastructure software, meaning normal conventions for application testing need to be adapted to quickly expedite the migration. Here are some important details:
- Every functional (e.g., smoke, UATs) and non-functional (e.g., performance, security) test should be executed only once on lower platform environments, e.g., SIT/QA. After passing the gauges, promotion to higher platforms should be seamless – additional compensation actions could be identified during validation as well.
- Test cases should be as automated as possible. Azul provides a tool to help run sanity checks as well as quick functional tests (smoke tests). This tool is provided as a Docker image.
- Nodes in a cluster set usually have the same configuration, application, and Java runtime configuration. Only one of the nodes is necessary to test (dry-run approach).
- E.g., if the cluster ring is composed of 10 nodes with similar configuration, only one should be selected for validation (usually the master node). If validation passes, migration to all remaining nodes in the ring is seamless.
- Cluster-level configuration (hot-bit, hot-swap, hot-standby, etc.) is dealt at the application level and not at the JVM level. This means the same strategy for test in other environments is applied here.
- Since we are not testing application functionality, only application infrastructure, a simple set of regression tests should be sufficient to validate the migration. These are the recommended test types for each test case:
- UAT for desktop applications (fat-clients only, e.g., Applets or JFX apps)
- Smoke tests for quick application functionality
- Performance tests (load and stress). Assuming performance SLAs are put in place.
- Quick sanity-checks to be ran just after migration (e.g., application started correctly, are all TCP/IP ports online after application initialization, etc.)
- Security tests for JDK 158 and lower. Black box tests are sufficient to validate the Java internal security configuration. If no security change was made to the Java runtime (security manager), applications running under an OOTB JVM security configuration should not be considered for testing – seamless migration bucket.
Non-functional requirements include things like development environments, performance SLAs, HA configurations, product, and versions.
If some teams are not available for meetings, you could also ask Application teams to complete a questionnaire or survey to help you understand your current Java footprint. Here are some examples.
| QUESTION | IMPORTANCE |
|---|---|
| What’s your application deployment strategy? Is it a client or a server application? | Java builds differ depending on OS, Which OS your app runs on helps us know which JRE/JDK builds we need to make available for evaluation, testing, and rollout. |
| If a server application, is it running on an application server? Is Java EE running on the server? | Java EE applications may need additional configurations due to their custom nature, e.g., specific libraries like Jasper may require additional server configuration, including the installation of Monotype fonts on the server side for processing text for generated images or PDFs. |
| If a client application, does your application uses Applets or Java Web Start? | This could quickly help you identify the Compensation actions to prepare the environment, e.g., Web Start uses DRS. |
| Does your application have support for TLSv3? | TLS 1.3 was only available for OpenJDK 8 as a part of OpenJSSE in updates prior to update 261 (because of backport compatibility from OpenJDK 11), and this is the only way to get it for some earlier versions. However, recent versions of JDK 8 (mainly update 261) do support TLS 1.3 even without OpenJSSE by simply switching some internal JVM configurations. |
| Does your application generate PDF reports, Images, QR codes, or use any graphics API? If so, what are the name of the frameworks used. | The generation of reports, images (in general), or any other graphics components uses the Java Graphics API (2D/3D). The graphics API requires that the font-types package is installed in the server side. Azul CCK (Compatibility Kit) is used to solve these missing components for Java 8. |
The purpose of these questions is to aggregate as much information as possible related to the application in question.
Although this step may appear similar to inventorying, these team meetings play a critical role in your migration process. To start identifying and remediating risks, you need a consolidated view of each application. Application owners may not have an in-depth understanding of the entire infrastructure of their organizations, but they know their application constraints. This step helps compile the information necessary to create a comprehensive view of your Java real estate, whereas taking an inventory may not yield all the information needed.
Inventory and classification in lower environments follow the same process as for controlled environments. Production environments may not have direct associations with application owners as lower environments do (e.g., development), but they have to be associated with the applications just like before. The key difference is that for those cases, additional stakeholders may be necessary in those meetings, including IT admins and DevOps specialists. We recommend performing those workshops in parallel, but the requirements for lower environments may not be the same as the ones for higher environments (e.g., stage). For those cases, the classification properties will have to consolidate these procedure changes as an additional requirement for the migration, e.g., development uses a single-purpose configuration, where a single Java runtime is configured for testing, but production uses a multi-purpose configuration, where multiple instances of the Java runtime are configured using single profiles (user basis installation).
OpenJDK Patch Update Strategy
Even though an Application Team meeting unlocks a more comprehensive view of your current Java estate, completing a thorough inventory still has a critical role in achieving a successful migration.
If your organization is like other organizations we have worked with, you have deployed your Java applications over an extended period of time — possibly even since the beginning of your organization. Typically, when a new application is deployed, it uses the latest version of the JDK and continues to use it even as newer versions of Java are released. Assuming the application works without issue, there is no requirement to continually update the JDK version. An upgrade of the Java version will only be required when security patches and bug fixes are no longer available for the version in use. This can introduce some possible problems, and it’s one of the main reasons lower environments have such old versions of the Java runtime.
On lower environments, the Java runtime is commonly deployed with the application as part of the CI/CD pipeline. Application owners usually have full control over the entire automation on these environments. Since the application is patched with the Java runtime, usually when those automation pipelines are stabilized, codebase changes are the only changes introduced to those environments and no change to the Java packages (version) happen. This means in most new app deployments (e.g., new docker image, or deploy to production), small maintenance patches to these environments don’t come with JVM patch updates (CPUs/PSUs).
During the migration project, it may be a good idea to separate or parameterize those pipelines to always follow the latest patch update (i.e., CPU) of the OpenJDK. This work may involve additional teams including IT administrators, DevOps architects, InfoSec or Governance.
NOTE: It’s also important to notice that OS based OpenJDK distributions (misc. distributions) may not have the latest patch available (specially for old Linux distros, i.e., vault distros). If the environment is configured using pacman, always make sure you have the OpenJDK repository of the distributor properly configured/added to your environment, e.g., https://docs.azul.com/core/zulu-openjdk/install/rpm-based-linux. This will help expedite your patch update strategy.
Securing the Java runtime with the latest patch may not be a priority for most applications, which is why it’s common for old “stable” application builds to use outdated JDK versions. Hence why it’s always a good idea to separate the control for patch updates from the application deployment strategy to the IT administration strategy.
Using Asset Management Tools
To create a complete inventory of JDK usage, examine each machine that runs any JVM-based applications. There are several market-based IT Asset Management tools that can be used to inventory your Java estate. These tools are often deployed to ensure that enterprises comply with licensing terms and conditions.
One common issue we find with these tools is that they do not always provide all the necessary information needed by the project, and sometimes (especially in Windows platforms) they provide only package-install based information, e.g., MSI in Windows or Pacman in Linux-based installations. Since Java in principle is a self-contained environment, simply unpacking its package makes the Java runtime functional. This means an extra effort may be needed to inventory all servers and desktops in your environment.
We recommend an “FS crawler” approach, search for every possible Java package installation in the environment. This is because sometimes, applications like to pack the Java runtime with the application installation/deploy. For those cases, most SAM tools will not identify the Java installation on these applications and ISV products.
In general terms, for each entry in the inventory, it’s good to have the following details about the JDK:
- FQDN: The fully qualified host name for future classification.
- Type: Physical machine (it is also helpful to indicate whether this is a server or desktop), cloud instance or container.
- Access details: Credentials for accessing a physical machine or cloud instance via a network connection with sufficient privileges to permit installation of the JDK. For containers, these details will relate to how the container image is generated. This will probably be via CI/CD tooling and should include information allowing a different JDK to be configured for inclusion in the image.
- Operating System: Which OS is in use with additional details. Typically, this will be a choice of Windows, Mac OS or Linux. Further information will include which version and, for Linux in particular, which distribution (so that the correct installation format can be selected). Finally, since some machines may be running old operating systems, it should be noted if the architecture is 32 or 64-bit.
- Install type: The JDK can be installed using several different methods, including system-wide installations, user specific installation, or even custom package installation.
- Custom App Configuration type: This is an important to indicate how the JDK is used with the applications.
- Application names: Associative entry, this should be used to identify all possible applications that use the current JDK package. For most cases this is a 1:1 relationship.
- JDK Version: This should also include the installed update level, for example, JDK 8u202.
- JDK Bitness: Some applications required a 32-bit runtime installation even if running a x64 machine.
- JDK Path: The path from which the application is installed. This is a very important piece of information since it can be used for classification of bundle JDK installations later in the migration process.
- Product Details: Name of all the products classified with the JDK installation.
- Environment Details: The JAVA_HOME, CLASSPATH and Path environment variables for both systemwide and user-based definitions. This can give important details on how the environment is configured.
- Registry entries for Windows: The JavaSoft registry information, which contains installation paths, active Java configuration, and the list of installed Java packages.
- JDK Publisher: Who is the implementor of the JDK provider, e.g., Oracle Corporation. This is important to flag which OpenJDK providers should be marked for migration and which ones are not.
- License information: Some JDK packages come with release information indicating what is the license assigned with the package installation, i.e., commercial.
We recommend the usage of ITAM tools for the first phase, collecting raw data from inventory. ITAMs are good for the first phase of broad categorization, but our next step involves a manual classification of these buckets, which provides a deeper analysis and ensures things are done diligently. Here are some sample recommendations from our experience with customers.
Using information from your Application Team Workshops, move the raw data into buckets. Your buckets will likely be unique to your needs, but you could choose buckets including:
| SAMPLE AUTOMATED BUCKETS | SAMPLE MANUAL BUCKETS |
|---|---|
| Possible migration | Ready for migration |
| Needs further clarification | Ready for migration |
| Bundled JDK | Marked for removal |
| Not used | Marked for removal |
| Looks like garbage |
Let’s pause for a moment to address platform environments (i.e., test, integration, development), which may not be as defined and organized as controlled environments (i.e., QA, stage, production). Be extra careful evaluating platform environments because usually there’s a one-off installation somewhere, where the Java runtime was simply unpacked or copied to without proper QA or documentation. Traversing the FS (crawlers) for these cases may be your only alternative if your ITAM system only provides information of packed installed information (e.g., from MSI installs or from the RPM database).
The JDK provides tools that can help you quickly identify important information that you can use during classification of the Java footprint. There are several ways to retrieve JDK information, including analyzing the “release” file of the JDK distribution, checking the Windows registry, using the JEP 223 (java -version/-showversion/-fullversion), Python scripts like “jcheck.py”, java system properties, jcmd/jmap, etc. Our preferred method is to retrieve this information directly from the Java runtime, e.g., using the “java.vendor” system property to find the OpenJDK publisher.
Another clever way to help initially classify the data being inventoried is to understand that for most cases, bundled JDK installations come as part of the installation path of the product. There are several ways to do this but defining “classification patterns” during inventory can be a quick way to infer which product is linked to which JDK. You could do this by either running a quick manual analysis after the inventory is done, or by applying pattern-based regular expressions during discovery.
Here are some examples of possible regular expressions (posix-based regex) that could be used to quickly map Oracle JDK product installations on Linux (separated by line):
r|opt|[Vv][0-9]+)\/.*[Oo]racle\/.*dbhome_?[0-9]+\/.*[Jj]([Rr][Ee]|[Dd][Kk]).*
.*\/(us?r?[0-9]+|usr|var|opt|[Vv][0-9]+)\/.*[Oo]racle.*\/(product|agent(_[.0-9]+)?|[Oo][Pp]atch){1,}\/.*[Jj]([Rr][Ee]|[Dd][Kk]).*
.*[Uu][0-9]+.*(\/|\\\\)[Oo][Rr][Aa]([Ii]nventory)?.*
.*\/[Oo][Rr][Aa].*((\/|\\\\)[Mm][Ii][Dd][Ll][Ee][Ww][Aa][Rr][Ee])?.*
^\/(opt|usr|var|(u[0-9]{1,2})).*\/([Oo][Bb][Ii][Ee][Ee]){1,}.*[\.\-0-9]*.*\/[Jj]([Rr][Ee]|[Dd][Kk]).*
.*(\/[Oo][Rr][Aa])?.*\/([Mm][Ii][Dd][Dd][Ll][Ee][Ww][Aa][Rr][Ee])?.*([Ww][Ll][Ss]([Ee][Rr][Vv][Ee][Rr])?).*(\/[Ss][Oo][Aa].*)?.*
.*[Oo]racle.*[Gg]rid.*These can be useful to rapidly infer not only what the JDK is being used for, but also to quickly classify the product that the JDK is bundled with. In the example above, typical Oracle products installations will be found. A script could evaluate these expressions on top of the inventoried Java estate and quickly classify the ones that match as “Java runtime for Oracle Products.”
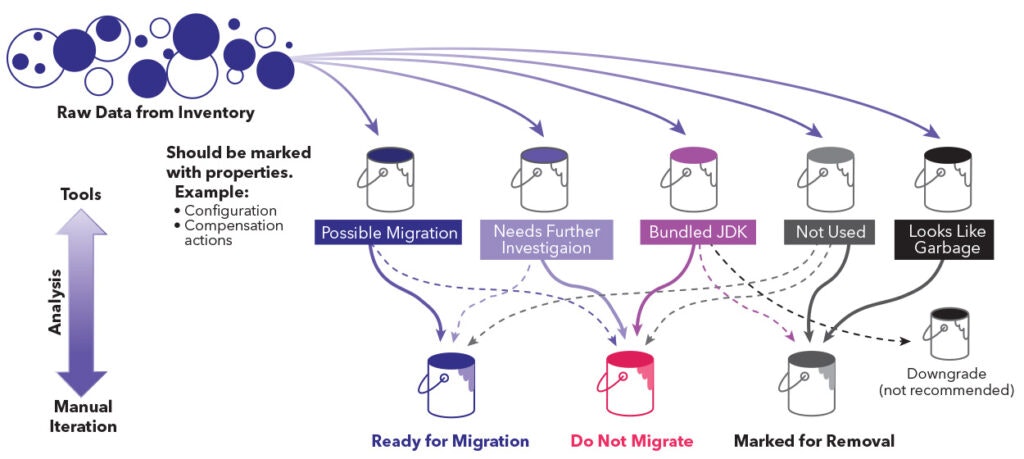
After the inventory is completed, it’s time to create the “migration buckets” to organize and prioritize the components from your inventory.
The first bucket is the first step of the classification, a quick identification of which Java runtimes can be filtered out from the estate. All JDKs that are marked as bundled with a product (e.g., given by the pattern matching above) should be placed in the “DO NOT MIGRATE” bucket, since they are already licensed with the ISV. All the other JDKs should be put into the “NEEDS FURTHER CLARIFICATION” bucket.
This process may remove a big chunk of installations discovered during inventory. After this first iteration is completed, notice that system-wide installations usually have the same patterns for both Windows and Linux alike. Package installations (i.e., MSI, RPM) follow the same pattern in both environments in terms of installation path, windows registry entries, symlinks, etc., which all can be used to put these JDKs from the “NEEDS FUTHER CLARIFICATION” to a new bucket that you can name as “POSSIBLE MIGRATION.” A similar technique to the one described above with installation patterns (regular expressions) can be used for this case.
You can fill the “LOOKS LIKE GARBAGE” bucket easily by analyzing the installation path for each extraneous entry. Here are some examples for what should be added to the garbage bucket:
- C:\$RECYCLE.BIN\S-1-5-21-725345543-131490\$R7POJLW.0_271\jre
- /u01/app/oracle/oem13c-decommissioned/agent_13.4.0.0.0/oracle_common/jdk
- /oracle/Middleware/Oracle_Home/oracle_common/jdk/jre.bkp
- C:\Program Files\Java\jdk13.0.1.bkp
OK you have filled the initial buckets, but you still need one more classification for the standalone JDK packages within the “POSSIBLE MIGRATION” bucket: the JDK installation counting. This number of Java runtimes in the footprint depends on how the inventory was prepared (e.g., done by traversing the filesystem) and the platform being analyzed (i.e., Windows, Unix), but for some cases this may not be a “realistic” number. A second level of filtering is needed to identify the correct installation counting. To accomplish this, the following ideas will stick:
- MSI Windows installations from certain JDK providers (e.g., Oracle) create a symbolic link for the installed JDK under the path “C:\Program Files\Common Files\” usually called “javapath”. This symbolic link points to the real JDK installations and it’s just an easy way to be quickly mapped to the entries defined in the CurrentVersion key in the Windows Registry.
- The Java Development Kit (JDK) usually comes with a version of the Java Runtime Environment (JRE) defined within. The usage of the JRE is restricted and under specific license condition (e.g., for development purposes only), so special attention with compliance is needed here.
- When installing the Java Development Kit (JDK), the JRE can be installed or not. By default, it’s installed within the same structure of the JDK, but this is not a rule of thumb, since it can be placed in other locations. For these cases, the JRE should be seen as a separate Java runtime installation from the JDK.
Here’s a functional example, the given examples below are part of the same Java runtime installation on Windows. This means they represent a “single” installation and not “multiple” installations of the same JDK:
- C:\Program Files\Common Files\Oracle\Java
- C:\Program Files\Java\jdk1.8.0_221
- C:\Program Files\Java\ jdk1.8.0_221\jre
To complete this initial discovery stage, create an additional inventory stage within the “POSSIBLE MIGRATION BUCKET” to mark all system-wide JDK installations. This can be easily done by analyzing the JavaSoft space in the Windows registry and running queries into Linux´ pacman repositories (e.g., rpm -q type of instructions). System-wide classified applications should be marked inside the bucket, since they will most likely be ready for migration.
Now that the inventory is done, you are ready for the second stage of Discovery, which is classifying all running Java applications. This stage will not only help clarify the running applications but also identify possible gaps between expected software versions and active versions.
Test Execution strategy (Validation phase)
Every organization will have its own strategy for development lifecycles. OpenJDK migration is an infrastructure software, meaning normal conventions for application testing need to be adapted to quickly expedite the migration. Here are some important details:
- Every functional (e.g., Smoke, UATs) and non-functional (e.g., performance, security) tests should be executed only once on lower platform environments, e.g., SIT/QA. After passing the quality gauges, promotion to higher platforms should be seamless – additional compensation actions could be identified during validation as well.
- Test cases should be as much automated as possible.
- Nodes in a cluster-set have usually the same configuration, application, and Java runtime configuration. Only one of the nodes are necessary to be tested (dry-run approach).
- E.g., if the cluster ring is composed of 10 nodes with similar configuration, only one should be selected for validation (usually the master node). If validation pass, migration to all remaining nodes in the ring is seamless.
- Cluster level configuration (hot-bit, hot-swap, hot-standby, etc.) is dealt at the application level and not at the JVM level. This means the same strategy for test in other environments is applied here.
- Since we are not testing application functionality, only application infrastructure, a simple set of regression tests should be sufficient to validate the migration. These are the recommended test types for each test case:
- UAT for desktop applications (fat-clients only, e.g., Applets or JFX apps)
- Smoke tests for quick application functionality validation (regression).
- Performance tests (load and stress). Assuming performance SLAs are put in place as part of the quality gauges.
- Quick sanity-checks to be ran during the migration execution (e.g., application started correctly, are all TCP/IP ports online after application initialization, etc.)
- Security tests for JDK 15 and lower. Black box tests are sufficient to validate the Java internal security configuration. If no security change was made to the Java runtime (security manager), applications running under an OOTB JVM security configuration should not be considered for testing – seamless migration bucket.
Example configuration for Test Suites
This should be a full set of test cases for one specific application, but instead only the relevant ones used to validate core application functionality. Example listing:
| APPLICATION NAME | TEST CASES | TEST TYPES | COMMENTS |
|---|---|---|---|
| B2B Web Application | TC01: Verify Login TC02: Verify Product Search TC03: Generate customer report |
Smoke tests | Using Azul’s MigTester with Protractor test suites |
| Search Engine | TC01: Quick Product Search | Smoke test |
Migration Stabilization
Stabilization is a post-migration activity. It’s defined by a set of monitoring activities used to identify possible inconsistencies (uncaught issues during validation) with the application environments after the migration was concluded. These are passive actions performed in conjunction with the migration team and each Apps team. It consists mainly of:
- Monitor ServiceDesk tickets for Java application errors (mostly for desktops):
- Periodically checks in the baseline application functionality.
- Periodically sample server logs for extraneous errors.
- Periodically interview selected application users for possible runtime inconsistencies.
Stabilization usually takes about a Month after the migration is concluded. Problems raised during stabilization are rare, and it usually means a missing compensation step during the migration. Plan to get to the latest CPU version as fast as possible.
Other than the Migration Engagement team to help identify these issues prior to the migration, Azul also has a 24x7x365 support to help solve any possible exception after the migration rollout is concluded.
Migration Post-Configuration
After the “like-to-like” migration is completed, a deep analysis about security needs to be considered. This analysis has the main purpose of identifying critical vulnerabilities that could exist in the current running Java SE version.
Upgrades should not change the major version (e.g., Java 8 to 11), but should be focused on minor version updates only (e.g., 8u201 to 8u382). Since migrating from a very old version to a newer build version may represent a deep impact in terms of level of service, a laddering strategy could be implemented.
One way to approach this is to find the nearest cumulative CPU package which contains most of the critical CVEs (scoring 9+), stabilized it, and finally move up in the ladder until it reaches the latest version. This process could take several Months depending on the number of servers and Java installations with old build numbers.
On every new patch update, JVM tuning may be necessary to comply with existing SLAs (e.g., security, performance, etc.). A good practice would be to classify the Java SE version based on the number of higher scoring CVEs identified in comparison to the target Java version to be deployed.
| JAVA VERSION | NUMBER OF INSTALLS | RELEASE DATE | IMPORTA# OF CVEs |
|---|---|---|---|
| 1.8.0_20 | 3 | September 2014 | 10 |
| 1.8.0_45 | 2 | April 2015 | 24 |
| 1.8.0_60 | 18 | August 2015 | 25 |
| 1.8.0_65 | 2 | October 2015 | 2 |
| 1.8.0_66 | 30 | October 2015 | 8 |
| 1.8.0_71 | 7 | January 2016 | 1 |
| 1.8.0_72 | 4 | February 2016 | 1 |
| 1.8.0_73 | 131 | March 2016 | 2 |
| 1.8.0_77 | 2 | March 2016 | 10 |
| 1.8.0_91 | 137 | April 2016 | 9 |
| 1.8.0_92 | 441 | May 2016 | 14 |
* List of CVEs scoring higher than 9 (9.3) found in patch update 8u92: CVE-2016-3610, CVE-2016-3598, CVE-2016-3587. The PSU 8u102 or CPU 8u101 patched these critical vulnerabilities.
For more information about CVEs please visit: https://docs.azul.com/core/cve
OpenJDK, Oracle, and Oracle JDK are property of Oracle Corporation.



