

Azul Zulu Prime (formerly known as “Zing”), part of the Azul Platform Prime offering, is based on OpenJDK with a few key enhancements to provide better performance. To name just a few, our Falcon JIT Compiler produces faster machine code and the C4 Pauseless Garbage Collector eliminates stop-the-world GC pauses. While you should continue reading how Platform Prime makes Apache Kafka faster, you can also try it out yourself.
We continue in our series of articles measuring performance of Azul Platform Prime against vanilla OpenJDK. In past articles, we have looked at a Renaissance benchmark and Apache Solr. Today, we look at Apache Kafka, the most popular event streaming platform in the Java community today. With the rise of event-driven architectures, Kafka brokers often serve as the central nervous system of the entire application. As such, it requires to handle large throughput (number of events per second) while keeping “reasonable” latency. Increasing Kafka clusters’ throughput capacity, therefore, became a large concern of the teams running the Kafka clusters.
In this blog post, we’re going to demonstrate that a simple switch of the underlying JVM can have a huge impact on Kafka throughput with minimal engineering effort. Additionally, we’ll look into possible gains in latency scenarios; we’ll discuss the typical bottleneck for Kafka and how to help it to become a low-latency message broker.
Apache Kafka measurement methodology
Our Kafka end-to-end benchmark measures producer and consumer throughput on a Kafka cluster. We run with three Kafka broker nodes and one node for Zookeeper. We also run the benchmark itself on the Zookeeper node. The below diagram summarizes the benchmark topology.
Hardware configuration is depicted in the table below:
| AMI | ami-0747bdcabd34c712a (Ubuntu 18) |
| Zookeeper instance | c5.2xlarge (1 GB Java heap) |
| Kafka broker instances | 3x i3en.2xlarge (40 GB Java heap each) |
| Load generation instance* | m5n.8xlarge |
The only OSS configuration we performed on the instances was to configure Transparent Huge Pages as we observed the best results with it:
$ echo madvise | sudo tee /sys/kernel/mm/transparent_hugepage/enable
$ echo advise | sudo tee /sys/kernel/mm/transparent_hugepage/shmem_enabled
$ echo defer | sudo tee /sys/kernel/mm/transparent_hugepage/defrag
$ echo 1 | sudo tee /sys/kernel/mm/transparent_hugepage/khugepaged/defragFor Kafka configuration, we used the following parameters:
| partitions | 3 |
| replicationFactor | 3 |
| producerThreads | 3 |
| consumerThreads | 3 |
| acks | 1 |
| messageLength | 1000 |
| batchSize | 0 |
| warmupTime | 600s |
| runTime | 600s |
Apache Kafka performance on Azul Platform Prime vs vanilla OpenJDK benchmark results
Throughput
We measured maximum throughput by increasing the load on the server by 5,000 requests per second until we reached the point at which Kafka could not reach the higher load. Maximum throughput in our tests was as follows:
Kafka Max Throughput (requests/sec)
| Azul Zulu Prime | 155,797 |
| OpenJDK | 107,805 |

Latency
In a typical Apache Kafka use case, the user is concerned about how many transactions that system can process while still operating “fine.” The definition of “fine” can be different, but the general sense is that the latencies of the processing are kept under acceptable SLAs. For Kafka, based on market research, we define “fine” in a way that the higher percentiles (P99) remains under 200 milliseconds, which still provides guarantees for a real-time system.
With that definition, we used the same benchmark, same setup, and same configuration mentioned above. We fixed the throughput and measured the end-to-end latencies for Kafka running on vanilla OpenJDK and Azul Platform Prime. If the latencies remained below the defined level (200 ms), we increased the throughput and repeated.
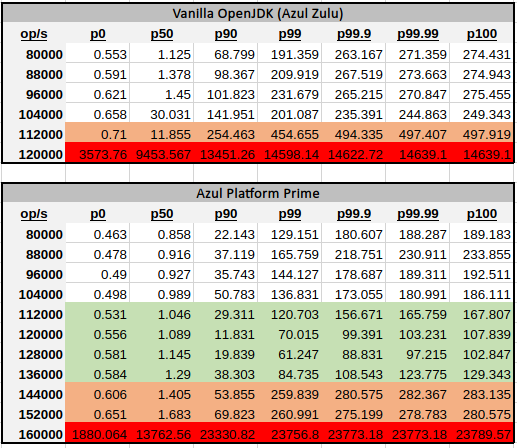
In the table above, you can observe that running Kafka on Azul Platform Prime enabled up to 136K operations per second while latency stayed comfortably beyond 200 ms, compared to 104K of OpenJDK which was touching the bar right from the beginning. That’s 30% improved usable capacity of the system, just by simply switching the JVM.
To provide more complete picture, Azul Platform Prime continued to operate “reasonably well” even with higher throughput untill 152K operations per second before the latency skyrocketed. Compare it to a vanilla OpenJDK run, where the latency went through the roof at 120K ops.
More observant reader is probably curious about the similarity of higher percentiles – there’s not much difference between P99 and the maximum. This is not a typical case how latency behaves and indicates that the bottleneck of the system is somewhere else other than the application itself. We drilled down further below, but long story short – disk speed and choice of the filesystem matters a lot for Kafka.
Lessons learned
Disk speed matters for Apache Kafka
During benchmarking, we realized that Apache Kafka is what we call a disk I/O bound workload – workload where disk speed is often a limiting factor. After all, this is also mentioned directly in Kafka’s official documentation:
The disk throughput is important. We have 8×7200 rpm SATA drives. In general disk throughput is the performance bottleneck, and more disks is better. Depending on how you configure flush behavior you may or may not benefit from more expensive disks (if you force flush often then higher RPM SAS drives may be better).
Kafka uses disk as a storage for the log segments. Whenever the log segment updates are rolled over to a new empty log, application threads get stalled, thus introducing latency spike (a phenomenon described in Kafka’s official JIRA). Below charts demonstrate the correlation between latency spikes and disks flushed. Note: These charts come from different diagnostics run and are not directly related to the above mentioned benchmark.
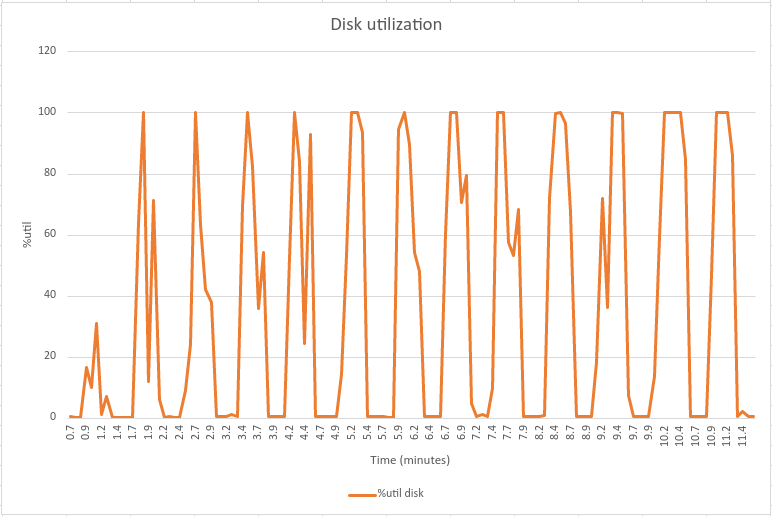
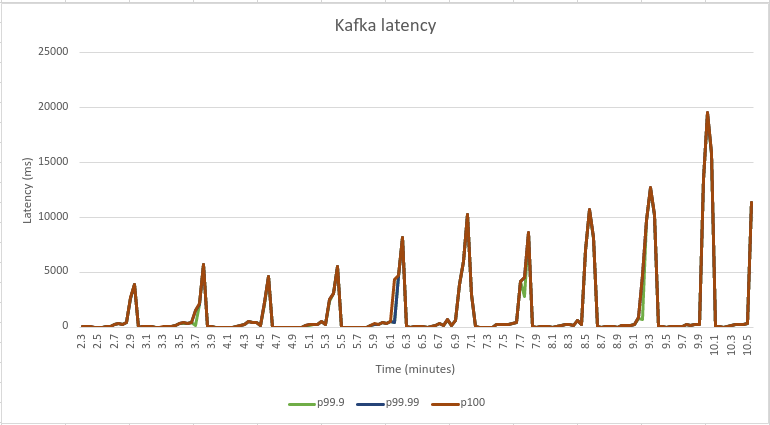
The data for these charts were collected using Linux tool sar (see sar documentation for more details). You can see that whenever there’s a latency spike in Kafka’s end-to-end latency, there’s also increased disk I/O activity.
The clear lesson here is to care about disk performance when running Apache Kafka, as it has significant effect on performance. This is why we used i3en AWS instance types – they are optimized for I/O with fast disks.
Choice of file system matters for Apache Kafka
If you read the above section, it probably doesn’t come as a big surprise that your choice of file system is a crucial aspect. When we tried to replicate Confluent’s latency benchmark, we initially struggled to get the same results in absolute latencies. Looking at the charts, we see that the 99.9th percentile is centered around 18 milliseconds, while we were seeing the same percentile consistently go up to even 300-500 milliseconds.
After deep investigation, we thought of changing the file system from ext4 (which is the default in Ubuntu) to xfs. All of a sudden, we started getting the same results – that’s an order of magnitude improvement!
Even better, now that we eliminated the disk I/O bottlenecks, Azul Platform Prime could really shine. Below are the charts replicating the exact latency scenario.

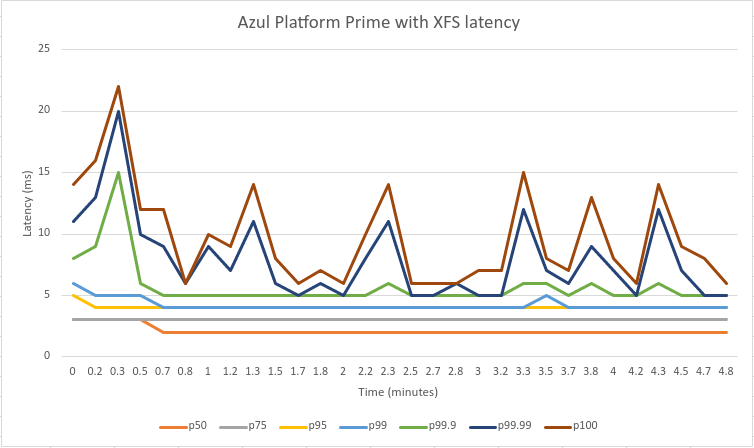
You can clearly see that all the high percentiles starting from the 99.9th and up were effectively cut in half, mostly being in units of milliseconds. Hence, we demonstrate on Confluent’s (not our) official benchmark that in combination with Azul Platform Prime, Apache Kafka can be the backbone of truly low-latency systems.
The practical ROI: reduction of Kafka cluster size saves money
Benchmark results are nice, but how do they directly impact your business? Given the results above, we found that a Kafka cluster of only three nodes running on Azul Platform Prime can carry the same load as a Kafka cluster of five nodes on vanilla OpenJDK. That’s two nodes fewer running all the time.
We can use this to calculate the direct money savings:
| vanilla OpenJDK | Description | Azul Platform Prime |
| $0.904 | AWS EC2 i3en.2xlarge hourly price | $0.904 |
| $7919.04 | Yearly price (1 node) | $7919.04 |
| 5 | Number of nodes in the cluster needed | 3 |
| $39595.2 | Total price per cluster (yearly) | $23757.12 |
| Total cost savings | $15838.08 |
It’s easy to see that the possible cost savings are non-trivial. It’s worth reminding how they can be achieved – by a simple switch of the underlying JVM. This is relatively simple compared to other techniques like scaling on demand, investing in application code optimization, or tuning Apache Kafka itself.
Summary
In this blog post, we showed a number of experiments that we conducted with Apache Kafka performance on Azul Platform Prime and compared Platform Prime against vanilla OpenJDK. We achieved roughly 40% improvements in performance, both throughput and latency. All those results were transformed into an example of practical calculation of how much money a user can spend optimizing the size of the Kafka cluster. We argue that switching the JVM to Azul Platform Prime is one of the easiest ways to do that. Lastly, we shared some lessons learned from our testing efforts.
Azul Platform Prime is available for free for testing and evaluation purposes via so-called Stream builds. The easiest way to see the benefits is to download them and try them yourself. Make sure to stop by at the Prime Foojay community forum to provide us the results you see.



