

当今的 Java 集群具有现代化、容器化和可弹性扩缩的特点,通常主要依赖 CPU 利用率来横向扩展新实例。尽管这一指标可能并不完美,但根据 CPU 利用率超过某个限制后就进行横向扩展新实例的做法却十分常见。该限制往往极低,大约在 40% 到 50% 之间。
Azul Platform Prime 使用 Falcon JIT 编译器取代了 OpenJDK 的 HotSpot C2 编译器。Falcon 生成的代码运行起来比 OpenJDK 快得多,因此,在达到 CPU 利用率限制之前,您可以在容器中处理更多事务。此外,Prime 在执行代码时更流畅、更一致,可以让您安全地将 CPU 利用率提高到 60-70%,从而大幅提高每个容器的承载能力,降低用于处理 Java 所有工作负载的总体云成本。
然而,一个经常出现的问题是,在 JVM 预热阶段,要如何平衡基于 CPU 的自动扩缩与 Falcon JIT 编译器对 CPU 的较大需求。许多自动扩缩程序会给 JVM 一小段预热宽限期(通常约为 1-2 分钟),然后就开始通过运行状况检查监控 JVM。如果在 1-2 分钟后,CPU 利用率超过一定比例(例如 50%),它们就会横向扩展,添加更多计算机。但是,如果 JIT 编译到那时还没有稳定下来,您就有可能在徒然扩展更多实例,因为 CPU 利用率高不是因为流量,而是因为 JIT 编译,而 JIT 编译很快就会衰减。这可能会导致您的集群陷入一个循环,即:集群不断启动新的计算机,认为它们已经积压很多负载,然后又启动更多计算机,如此反复。
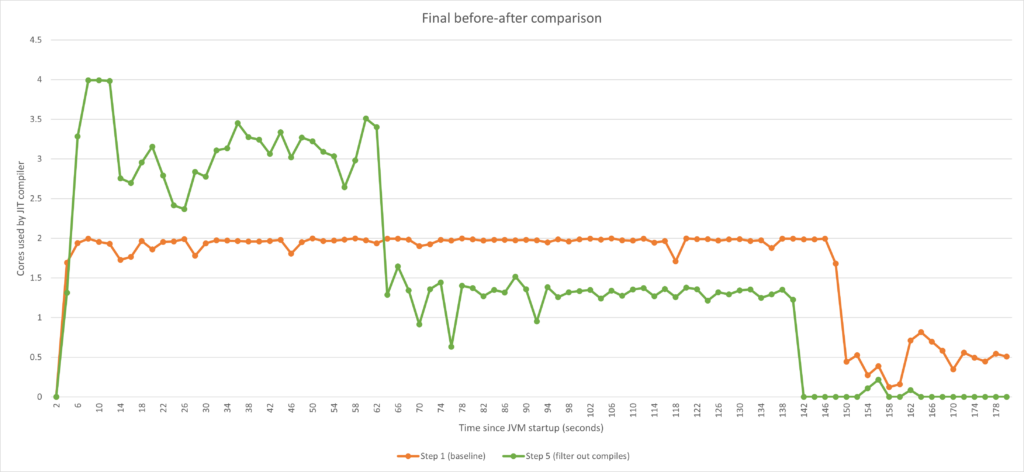
在本文中,我们将探讨 Azul Platform Prime 如何平衡 JIT 编译的 CPU 开销和基于 CPU 的自动扩缩,从而在提供最高性能的同时避免出现这些令人头疼的扩缩相关问题。下图是前后对比的摘要。我们来逐步了解一下。
第 1 步:开启运行之旅
我们来使用前面提到的场景:启动 Java 工作负载,将 JVM 稳定性能/CPU 利用率的阈值(即所谓的“后预热阶段”)设置为 1 分钟。1 分钟过后,如果 CPU 利用率超过某个阈值(例如 50%),则激活自动扩缩程序以进行纵向扩展。作为 JVM 的运营者,我们无法控制应用程序本身消耗多少 CPU(这取决于负载)。因此,我们的目标是控制 JIT 编译器在预热后阶段消耗的 CPU,以确保扩展是由于负载增加,而不是由于 JIT 活动。
下图展现了该编译器处理某 Java 工作负载时的 CPU 利用率。
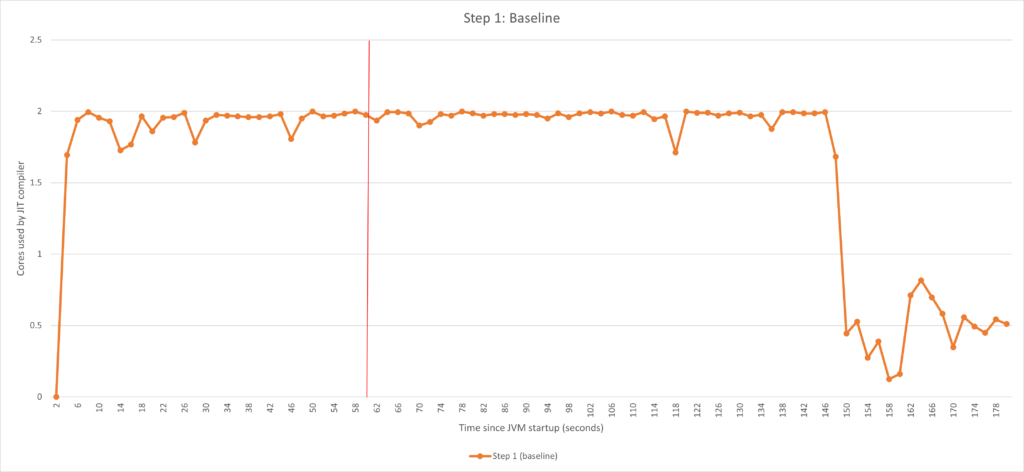
从图中我们可以看到,编译器在 1 分钟(60 秒)限值后仍然非常活跃。这是因为可能还有一些方法尚未达到编译阈值,或者编译器队列被最初爆发的活动占满了。
为了实现我们的目标(在 60 秒后最大限度减少 JIT 编译器活动),遵循的主要策略如下:
- 建立基准。
- 使用 ReadyNow 在运行初期尽可能多地预先加载优化。我们已经通过 ReadyNow 知道需要哪些优化,甚至可以在首次调用方法前就开始进行优化,而不是等到它们达到编译阈值后再进行。
- 使用 -XX:CompilerWarmupPeriodSeconds 标记,设定 1 分钟的预热时间。然后我们可以利用
-XX:CompilerTier2BudgetingWarmupCPUPercent=100给编译器更多资源,让它在预热时间内做更多工作。因此,在运行状况检查启动之前,我们会投入最多资源来解决编译工作负载问题。 - 限制 JVM 在预热时间后可用于编译的 CPU 用量。我们可以通过
-XX:CIMaxCompilerThreads使用线程计数进行静态限制,或使用-XX:CompilerTier2BudgetingCPUPercent标记按可用 CPU 的百分比进行动态限制。 - 通过筛选出花了太长时间(例如超过 1 分钟)才达到编译阈值的方法,进一步减少编译数量,如此筛选出的方法意味着它们不是“真正热门的”方法。为此,我们要使用
-XX:TopTierCompileThresholdTriggerMillis标记。
接下来,我们逐一详细了解这些方面,查看每一步的效果。
第 2 步:使用 ReadyNow 尽快编译
JVM 启动后,便要尽快开始编译。我们的最终目标是在自动扩缩程序开始监控之前尽可能多地编译,最好是全部编译完毕。为此,开始时我们要利用 ReadyNow,它可以实现以下两点:
- 减少编译总量,因为 JVM 已经从上一次运行中知道哪些推测是错误的,因此在后续运行中可以完全跳过。
- 在方法被调用之前就开始编译。通过提前启动编译,JVM 就可以提前完成编译。
我们来看看 ReadyNow 的实际效果。
使用的 JVM 标记
-XX:ProfileLogIn=<path to ReadyNow profile>
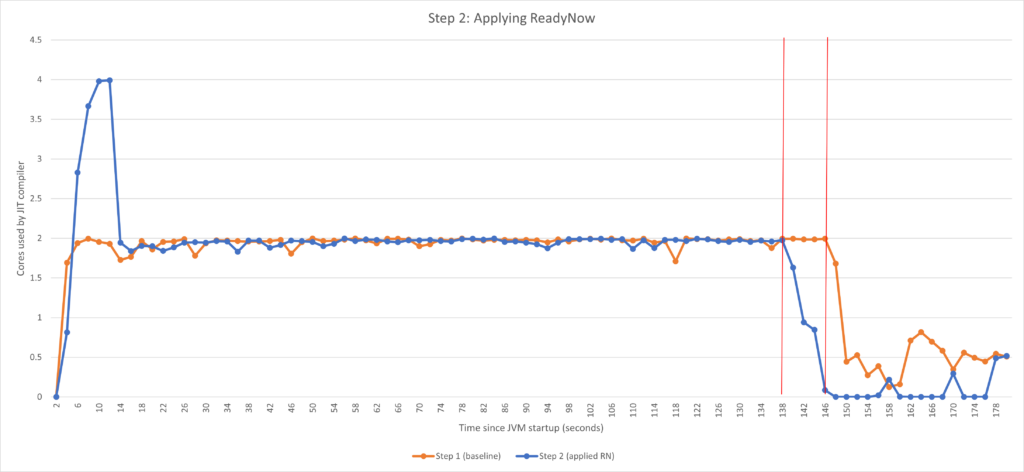
应用 ReadyNow 后,我们发现两点:
- 预热时间缩短了大约 10 秒。这主要是因为运行开始时的活动量变为两倍,因此我们得以提前完成一些工作。当开启 Azul 的 ReadyNow Java 预热功能时,Azul Platform Prime 会默认在编译的前主要阶段增加两个线程,您可以看到正好又有两个核心被使用。再清楚说明一点。在这一特定例子中,我们实际上无法看到 ReadyNow 提前启动编译的真正优势,因为这是一个反复做一件事的合成基准,而不是有不同执行阶段的真实应用程序。真正的优势来自添加资源(可通过
-XX:ProfilePreMainTier2ExtraCompilerThreads进一步调整)后的默认行为。但通常来说,使用 ReadyNow 对于获得最佳行为至关重要。 - 预热后活动明显减少。另一方面,在这里我们看到 ReadyNow 已全力发挥作用。而预热后活动减少是因为没有执行从先前运行中已知不需要的编译活动。
以此作为检查点,我们得以稍微缩短预热时间,并获得明显有改善的预热后行为。但是,我们离 1 分钟的目标还很远。我们还能做得更好吗?
第 3-4 步:调整预热期间和预热后的可用 CPU
指定预热时间
指定预热时间实质上是为了告诉 JVM,从 JVM 启动开始,有一段时间间隔它需要特别处理。所谓特别处理,是指能够为 JIT 编译器设置另一个 CPU 限制(仅举一例)。下面我们将预热时间设置为到自动扩缩程序开启 CPU 监控时为止。在那之前,我们会尽量使用更多 CPU 来编译更多方法。但是,当预热时间结束,我们会限制可用 CPU 的数量,以控制开销并维持在所需的 CPU 限制范围内。
要指定在哪一时间段需将额外 CPU 能力用于编译,请使用以下标记:
- -XX:CompilerWarmupPeriodSeconds:设定 Falcon 编译器预热时间的长度(秒)。默认值为 0。
指定预热时间后,我们就可以按照上文所述调整可用资源了。为此,我们使用构建的 CPU 预算功能,该功能可以让我们非常精细地限制 CPU 资源,甚至能限制核心/硬件线程中的各部分。
控制 JIT 编译器占用的 CPU 资源
指定可用 CPU 资源的最常用方法是以可用 CPU 总量的百分比作为基准。所谓“可用 CPU”,是指在裸机上运行时的核心数量。在有各种可能的容器限制的容器中,相关计算略为复杂。
我们可以使用以下选项设置编译器的 CPU 限制:
- -XX:+EnableTier2CompilerBudgeting:启用 CPU 预算功能。
- -XX:CompilerTier2BudgetingCPUPercent:指定在预热后阶段可用于编译的 CPU 用量(占可用 CPU 总量的百分比)。得出的值可小于一个核心或为核心的任何其他非整数。然后,Falcon 编译器就会受到限制,使其消耗的资源不超过此处指定的百分比。
- -XX:CompilerTier2BudgetingWarmupCPUPercent:与上述选项类似,指定预热期间可用于 Falcon 编译的 CPU 用量。
举个简单的例子:在一台有 8 个核心的计算机上,如果编译器的 CPU 预算为 40%,那么系统将为 Falcon 编译器分配 3.2 个核心。
接下来,我们看看这些标记的作用。
在预热期间添加资源
首先,我们在预热期间为编译器添加更多 CPU。我们将预热时间设置为 2 分钟(不是 1 分钟,稍后会解释),并允许编译器使用所有可用 CPU。
JVM 标记
-XX:+EnableTier2CompilerBudgeting-XX:CompilerWarmupPeriodSeconds=120 -XX:CompilerTier2BudgetingWarmupCPUPercent=100 -XX:ProfileLogIn=<path to ReadyNow profile> |
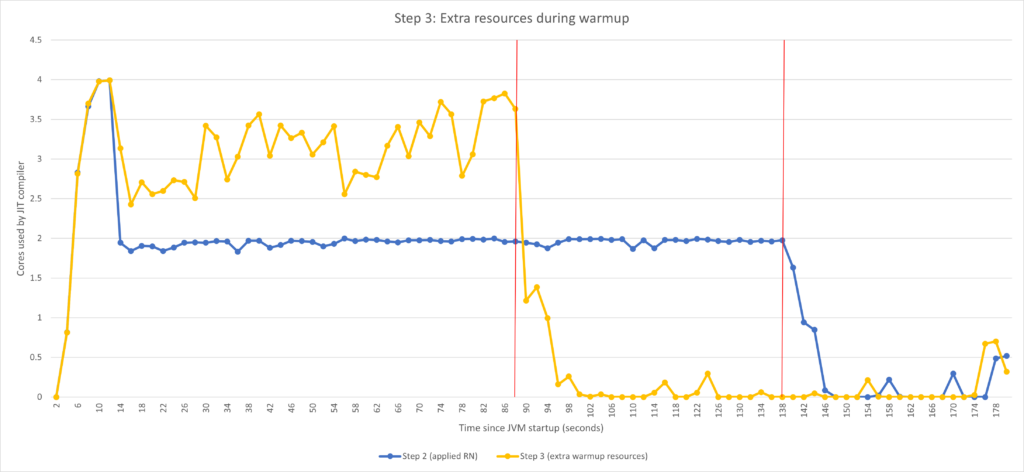
借助 -XX:CompilerTier2BudgetingWarmupCPUPercent=100,Falcon 编译器在预热期间会使用所有可用 CPU。与此形成鲜明对比的是,在默认情况下,启发式方法不会为 Falcon 编译器分配如此多的 CPU 资源。
可以看到,预热时间从大约 140 秒大幅缩短到大约 90 秒。由于我们在开始运行时允许编译器使用更多资源,因此它能够更快完成工作。如果将自动扩缩程序配置为在 100 秒后就开始监控,我们的探索之旅可能就到此结束了。但事实并非如此。
注:下面解释之前为何将预热时间设为 2 分钟。我们知道如果增加资源,编译器就能在这段时间内完成所有工作。那时我只是想展示增加资源的效果,而且这可能还不够,所以我选择了一个足够长的时间间隔来完成所有工作。
限制预热后的资源
鉴于一开始的目标是在 60 秒后控制编译器的 CPU 利用率,从上一个图中我们仍然可以看到,有很多活动会导致自动扩缩程序过多添加计算机。因此,我们也要调整预热后的 CPU 利用率。
JVM 标记
-XX:+EnableTier2CompilerBudgeting-XX:CompilerTier2BudgetingCPUPercent=33 -XX:CompilerWarmupPeriodSeconds=60 -XX:CompilerTier2BudgetingWarmupCPUPercent=100 -XX:ProfileLogIn=<path to ReadyNow profile> |
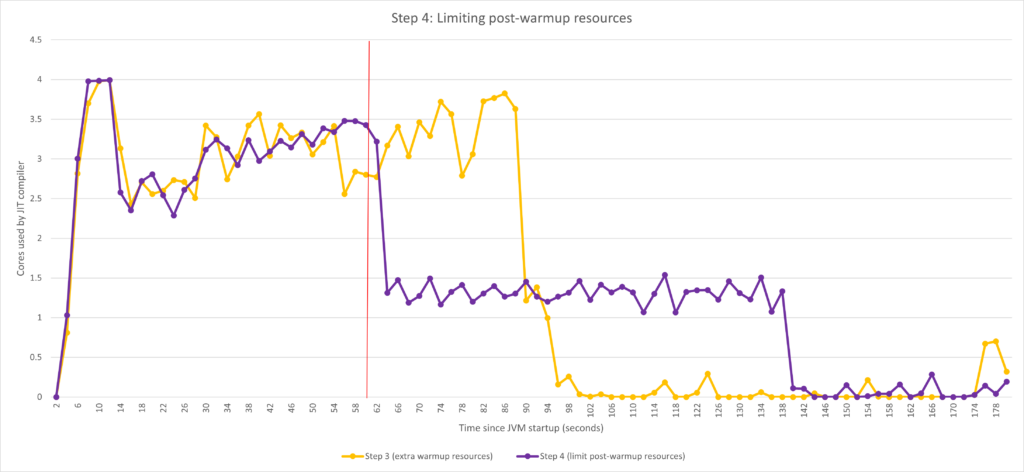
预热时间过后,编译器的可用 CPU 会受到 -XX:CompilerTier2BudgetingCPUPercent=33 的限制,这使得 CPU 利用率在 60 秒指标后大大降低。
扩展还是不扩展,这是一个问题
现在非常适合提醒一下自己,这是一个关于平衡的行为。第 3 步和第 4 步之间的编译量是相同的,只是分散在不同的时间段。您可能会说,在自动扩缩程序开始监控后的一段时间内,较晚完成编译实际会导致性能降低(与最终达到的最佳性能相比)。您的想法是对的!不过,问题是这种影响有多大,并且是否值得。下面我来详细说明。
根据上图,自动扩缩程序开始监控时,核心利用情况保持在 60 秒指标的范围内。考虑一下这种情况:JIT 编译器使用两个以上核心时会导致 CPU 总利用率超过阈值,进而让自动扩缩程序倾向于横向扩展。对于第 3 步的行为,自动扩缩程序会在 60 秒后立即开始大幅自动扩展,之后可能会缩小规模。对于第 4 步配置,自动扩缩程序完全不会横向扩展,而是继续以较低性能(与最佳性能相比)运行一段时间。
我们认为,在大多数情况下,避免自动扩缩实际是有益的,原因有两个:
- 要知道,自动扩缩通常会对性能造成不小的影响,例如,由于重新平衡数据、建立连接等,更不用说还会导致基础设施成本增加了。
- 在一段时间内,较低的性能实际上可能已“足够好”,而且只会越来越好。如下图所示,在 60 秒内,我们完成了约 75% 的编译工作。因此,我们有理由相信,您最终会达到“足以启动的良好”性能。需要明确的是,完成 75% 的编译并不意味着达到最佳性能的 75%,而这其实是另一个话题了。
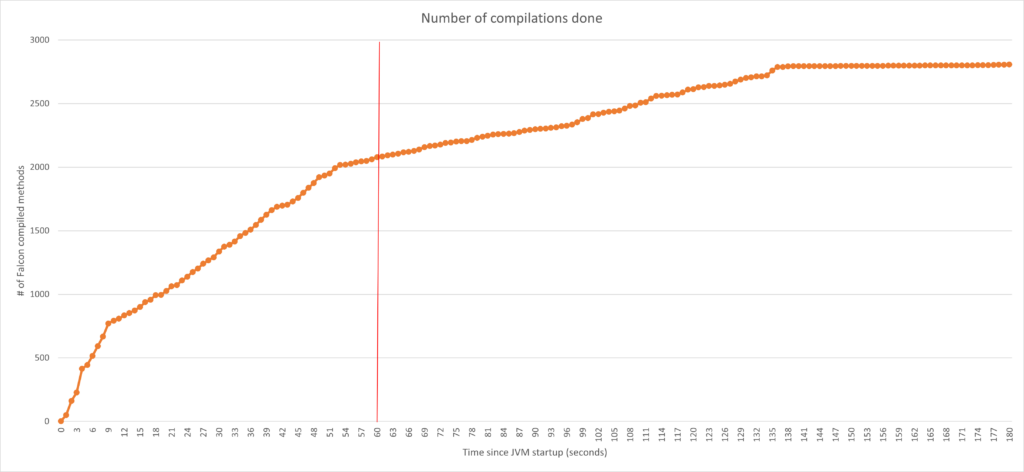
这些方面需要针对具体应用进行测试和评估。不过,此处的一大要点是,与其他任何 JVM 不同,Azul Platform Prime 能提供多个工具供您选择。根据我们的经验,在使用得当的情况下,您可以实现好得多的行为,不仅可以节约资金,还可以减少自动扩缩带来的不必要影响(例如,由于违反 SLA 而导致的错误)。
为了锦上添花,我们来试着再稍微优化下编译活动。
第 5 步:进一步降低编译量
编译阈值简介
JVM 会监控每个方法,并开始构建一个包含方法被调用的次数的配置文件。编译阈值规定了一个方法必须被调用多少次后才会被添加到 Falcon 编译队列。这是编译器优化理论中的一个重要因素,因为不常用的方法不需要优化。我们可以只关注经常被调用的方法,从而节约资源。我们使用 -XX:FalconCompileThreshold 来设定编译阈值。编译阈值规定了一个方法(或方法中的循环)必须被调用多少次后才会被添加到 Falcon 编译队列(默认为 1 万次)。不过,直接调整该阈值属于非常高级的调整,一般不建议使用。我们来看看另一种方法。
仅编译常用热门方法
虽然编译所有达到编译阈值的方法(这是默认行为)对代码优化很有帮助,但仍然会对系统资源带来不必要的负担。试想某个方法在 JVM 的生命周期中一直是偶尔被调用一次。由于该方法被调用的频率仍然较低,最终会达到阈值并被安排进行编译。不过,我们可以认为,由于该方法只是偶尔被调用,意即它并不“热门”,因此可能不会对应用程序的整体性能产生明显影响。所以,我们可以认为,用 Falcon 的各种优化方法编译该方法纯粹是浪费资源。
正因如此,Azul 在 Optimizer Hub 和 Azul Platform Prime 中应用了一个选项,让编译器仅在某方法在指定时间内达到编译阈值时,才将其加入编译队列。这样可以确保只有“热门”方法(即,仍被经常调用的方法)才会被安排进行优化。达到编译阈值的时间限制通过以下命令行参数指定:
- -XX:TopTierCompileThresholdTriggerMillis:当某方法在指定时间内至少达到一次编译阈值(由
FalconCompileThreshold指定)时,让编译器将该方法添加到 Falcon 编译器队列。时间值以毫秒为单位。例如,将TopTierCompileThresholdTriggerMillis设置为 60,000 时,只有当该方法在过去一分钟(60,000 毫秒)内被调用 10,000 次(默认编译阈值)时,编译器才会将该方法加入 Falcon 编译器队列。
JVM 标记
-XX:TopTierCompileThresholdTriggerMillis=60000 -XX:+EnableTier2CompilerBudgeting-XX:CompilerTier2BudgetingCPUPercent=33 -XX:CompilerWarmupPeriodSeconds=120 -XX:CompilerTier2BudgetingWarmupCPUPercent=100 -XX:ProfileLogIn=<path to ReadyNow profile> |
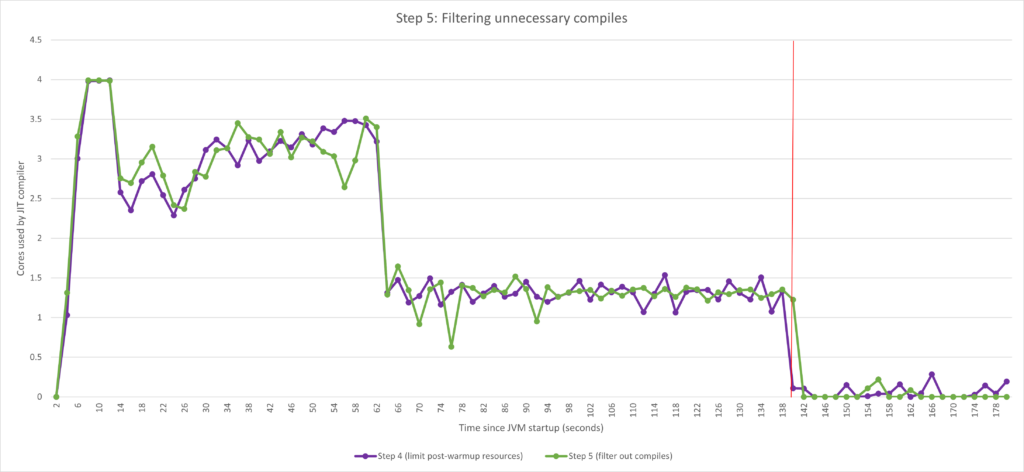
设置 -XX:TopTierCompileThresholdTriggerMillis 的效果尤其体现在运行后期 JIT 编译器的 CPU 利用率降低时。在上图中,比较一下大概 140 秒后峰值出现的次数。这很可能是因为所有重要的方法在那时都已编译完毕,通过过滤掉不太热门的方法,编译器的工作量减少了。
显然,使用该选项是一种微调。如果将这一时间间隔设置得太短,编译器可能会放弃过多方法,从而影响性能。根据我们的经验,针对基于 Spring Boot 的微服务等实际应用程序,在开始时设置 60 秒的时间阈值是个不错的选择。
最终比较
为总结本文内容,我们再看看前后对比图。
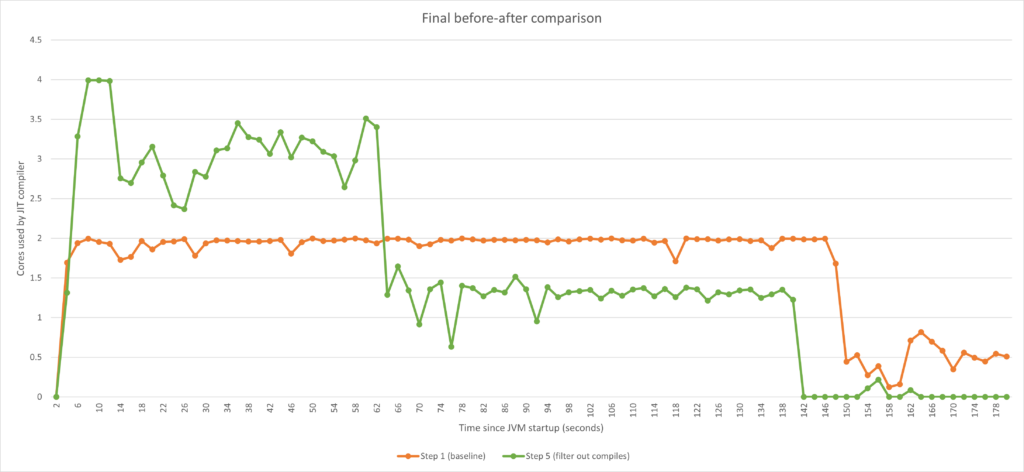
我们可以清楚看到,在应用了本文概述的所有调优方法后,我们得以精细控制编译器的 CPU 利用率,并优化 CPU 负载,实现在 60 秒后降低 CPU 负载的目标。在尽量避免进行不必要的扩展的同时,我们还优化了总预热时间,从而更快获得最佳性能。
请亲自尝试,并随时联系我们!
Azul Platform Prime 可免费下载并在非生产环境中进行测试。欢迎试用,也欢迎联系我们。Azul Platform Prime 不仅仅能管理 CPU 活动(如本文所示),还能让应用程序的性能大幅提升,实现高吞吐量、低延迟,并让您能够控制基础设施的成本。
附录 A:通过线程计数控制编译器占用的 CPU 资源
JIT 编译器对 CPU 资源的控制历来是通过调整线程计数(与本文展示的 CPU 百分比限制相比)来实现,因此为求全面,应提到这些选项。不过,我们选择列出这些选项不仅仅是为了全面。在一种非常特殊的用例中,通过线程计数调整 CPU 资源比使用 CPU 预算功能更合适。该用例就是当 JVM 在容器中运行,并设置了 CPU 限制而导致 CPU 节流时。这个话题本身值得用一整篇文章来探讨,但在本文中,为节省篇幅,我们简单说明一下。
CPU 节流造成的延迟(延迟异常)通常大于调度延迟(线程争夺 CPU 时间),这是因为节流会暂停所有进程的线程,而调度延迟只会暂停一部分线程。总之,如果 CPU 出现严重节流,您可以考虑通过线程计数来调整资源。如果您对这个话题感兴趣,请告诉我们,我们可以深入探讨。
用于控制 Falcon JIT 编译器线程计数的选项包括:
- -XX:CIMaxCompilerThreads:设定可专用于编译器的 CPU 线程数。这将告诉编译器有多少线程(最大值)应该用于编译。默认值取决于 CPU 数量。
- -XX:CompilerWarmupExtraThreads:允许 Falcon 编译器在预热期间超过最大线程数。该选项可设定 Falcon 编译器在预热期间在
CIMaxCompilerThreads上可以使用的额外线程数。预热后,应限制在CIMaxCompilerThreads的值内。默认值为 0。 - -XX:ProfilePreMainTier2ExtraCompilerThreads:设定 Falcon 编译器在执行
main()方法之前在CIMaxCompilerThreads上可以使用的额外线程数。


